
SDXL fine-tuned on The Babadook trailer

Video object segmentation for short and long videos

Source: Neuronovo/neuronovo-7B-v0.3 ✦ Quant: TheBloke/neuronovo-7B-v0.3-AWQ ✦ Neuronovo/neuronovo-7B-v0.3 model represents an advanced and fine-tuned version of a large language model, initially based on CultriX/MistralTrix-v1.

Ginetta.net office photos fine-tuned on SDXL

A 14B parameter, lightweight, state-of-the-art open model trained with the Phi-3 datasets that includes both synthetic data and the filtered publicly available websites data with a focus on high-quality and reasoning dense pro

The Yi series models are large language models trained from scratch by developers at 01.AI.
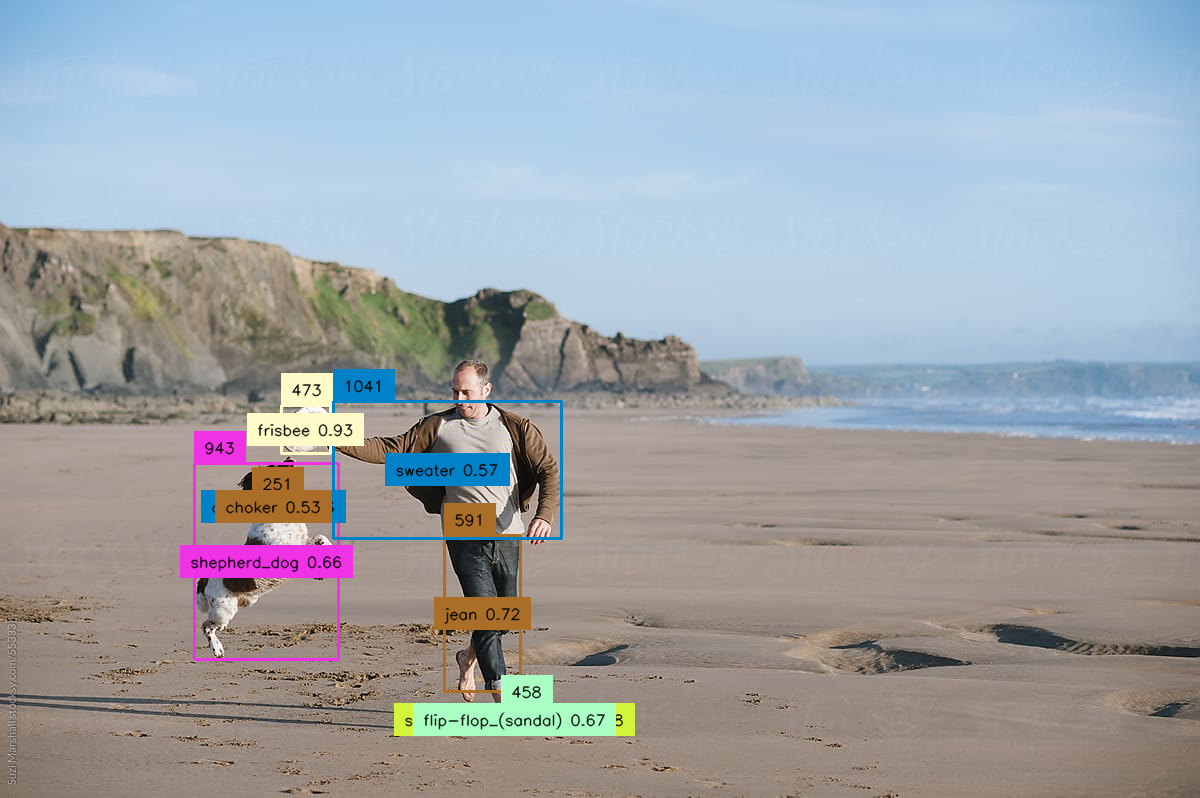
Detects objects in an image

High quality image blending using Kandinsky 2.2 blending pipeline brought to you by your best friends at FullJourney.AI :)

Generate a new image from an input image with DreamShaper V6

Consistent view characters with ControlNet and Stable Diffusion fine-tuned on Ready Player Me characters based on OpenJourneyV4

BLIP2 model trained on blip2-flan-t5-xl-coco dataset

Cog wrapper for Ollama llama3:8b

Image Mixer Stable Diffusion

AI Music Structure Analyzer + Stem Splitter using Demucs & Mdx-Net with Python-Audio-Separator

SDXL finetuned on line art

Simple video chroma keying
Generate high resolution image

An SDXL model Finetuned for style on Marker-Style Sketches

My own personal fork of Stable Diffusion

Predictive CFD from 2D input
