
Realistic interior design with text and image inputs

About Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation

Playground v2.5 is the state-of-the-art open-source model in aesthetic quality

A SDXL inpainting model that can be used for Replicate finetuning

Demo for AnimeGanv2 Face Portrait

Fast Diffusion for Image Generation, ~3 Seconds

T4 GPU, negative embeddings, img2img, inpainting, safety checker, KarrasDPM, pruned fp16 safetensor
Yi-1.5 is continuously pre-trained on Yi with a high-quality corpus of 500B tokens and fine-tuned on 3M diverse fine-tuning samples

Qwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data
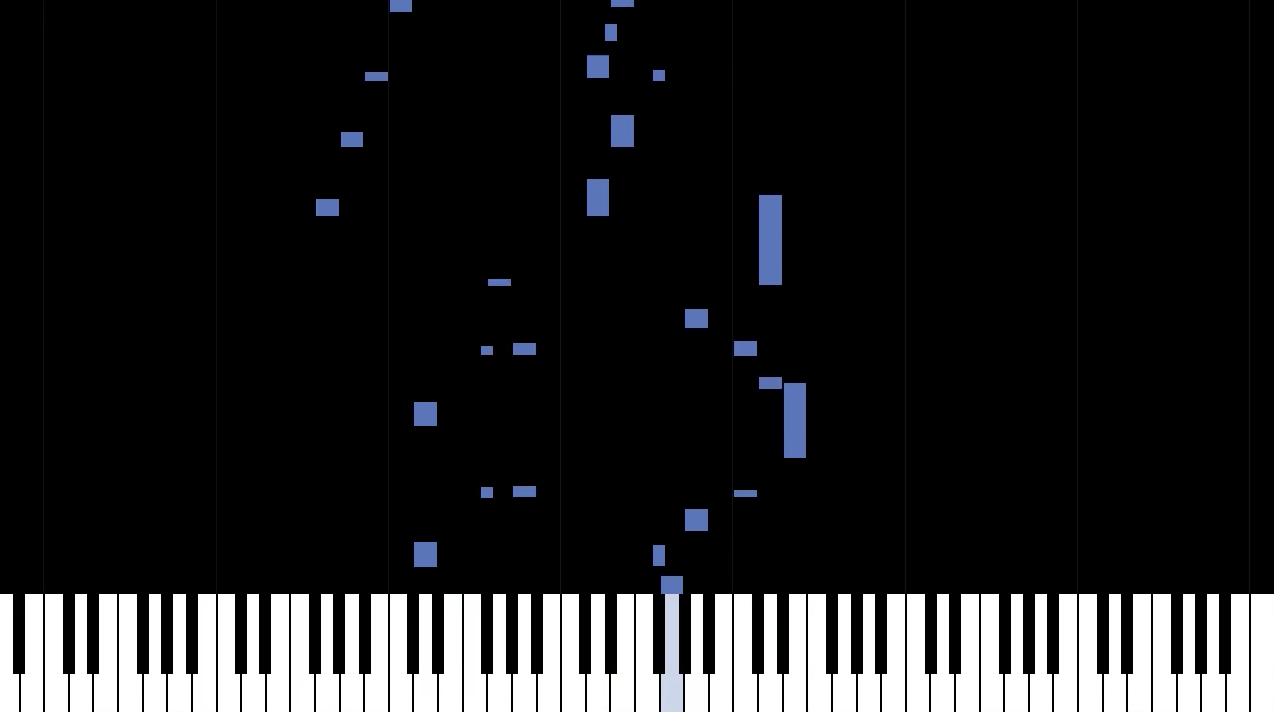
high-resolution piano transcription system: detects piano notes from audio

DPO-SDXL Canny controlnet with LoRA support.

ZooZoo Images

Generate an image by specifying a different text prompt for each region

lmsys/vicuna-7b-v1.3
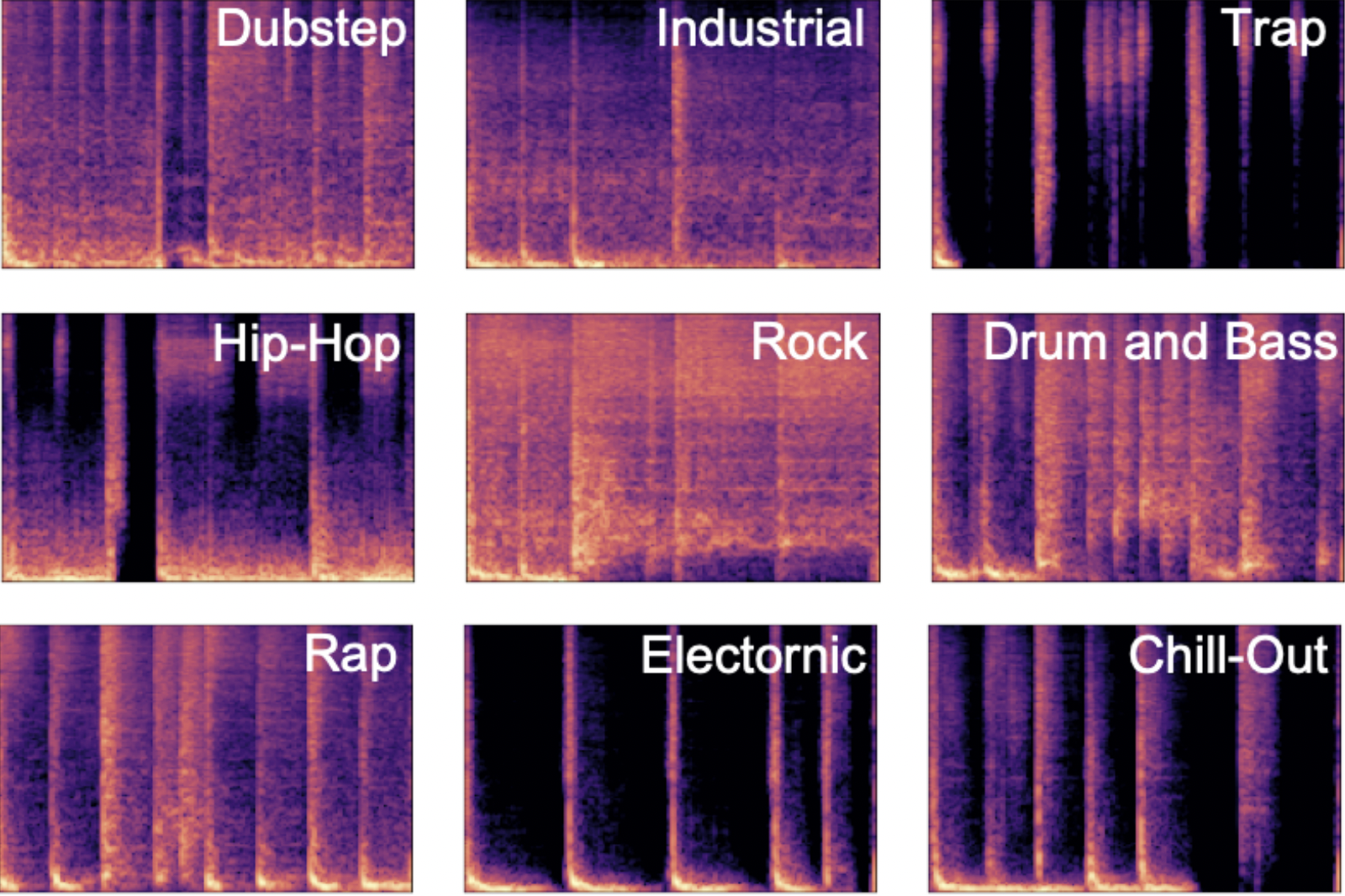
Four-bar drum loop generation

Online demo for "Orthogonal Jacobian Regularization for Unsupervised Disentanglement in Image Generation"

Archer on Stable Diffusion via Dreambooth

Base version of Mamba 2.8B Slim Pyjama, a 2.8 billion parameter state space language model

FlashFace: Human Image Personalization with High-fidelity Identity Preservation

shap-e running on replicate a100
