A language model for tasks like classification, summarization, and more.
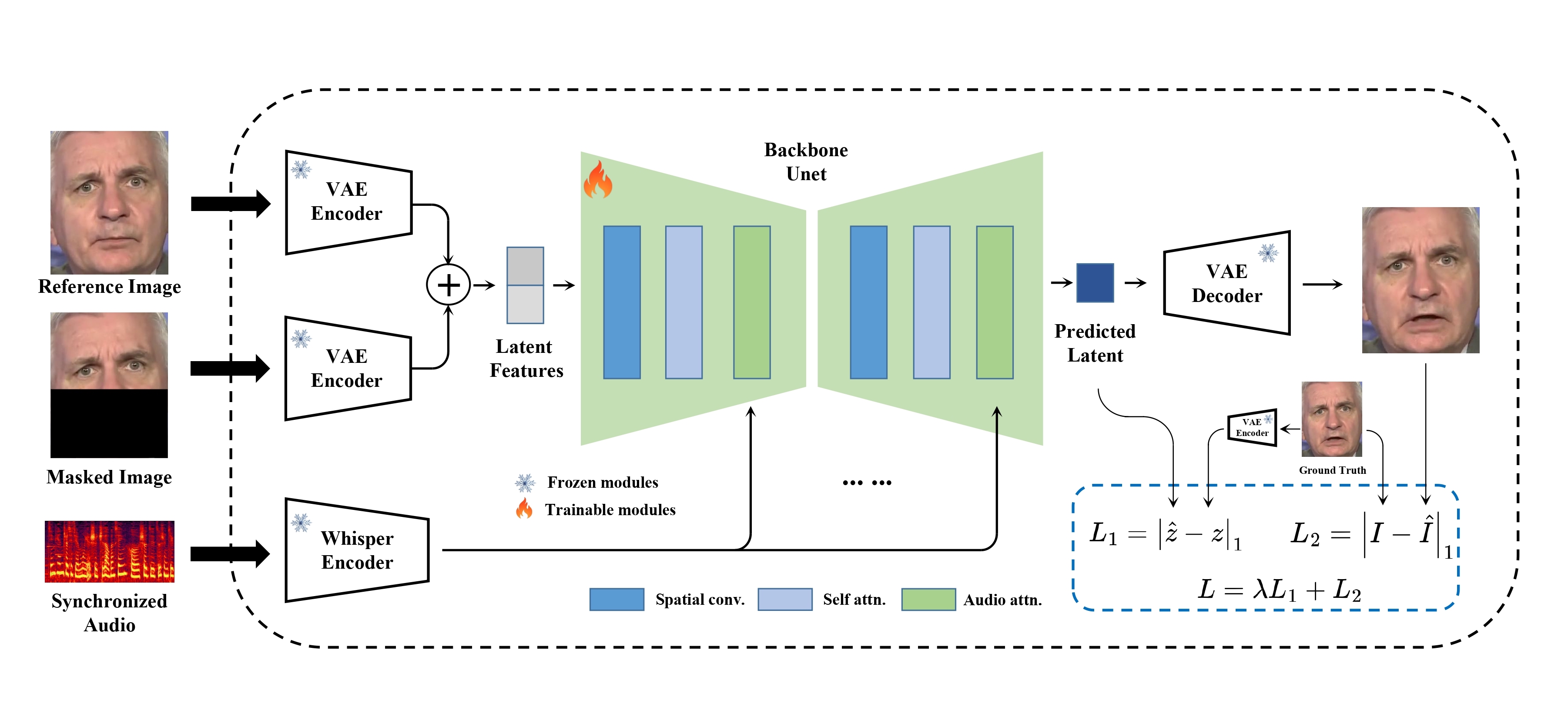
Real-Time High Quality Lip Synchronization with Latent Space Inpainting

Generate images quickly with GLID-3 (non-xl)

ControlNet implementation for RunDiffusion's PhotorealisticFX model.

Source: TokenBender/evolvedSeeker_1_3 ✦ Quant: TheBloke/evolvedSeeker_1_3-AWQ ✦ A fine-tuned version of deepseek-ai/deepseek-coder-1.3b-base on 50k instructions for 3 epochs

CRM: Single Image to 3D Textured Mesh with Convolutional Reconstruction Model

SD 1.5 trained with +124k MJv4 images by PromptHero
Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding

Paintings in the style of selected artists with weights, from the Construction Series of GymDreams8.

Versatile Audio Super-resolution at Scale which upsamples audio files to 48khz. Longer audio input is possible with this model
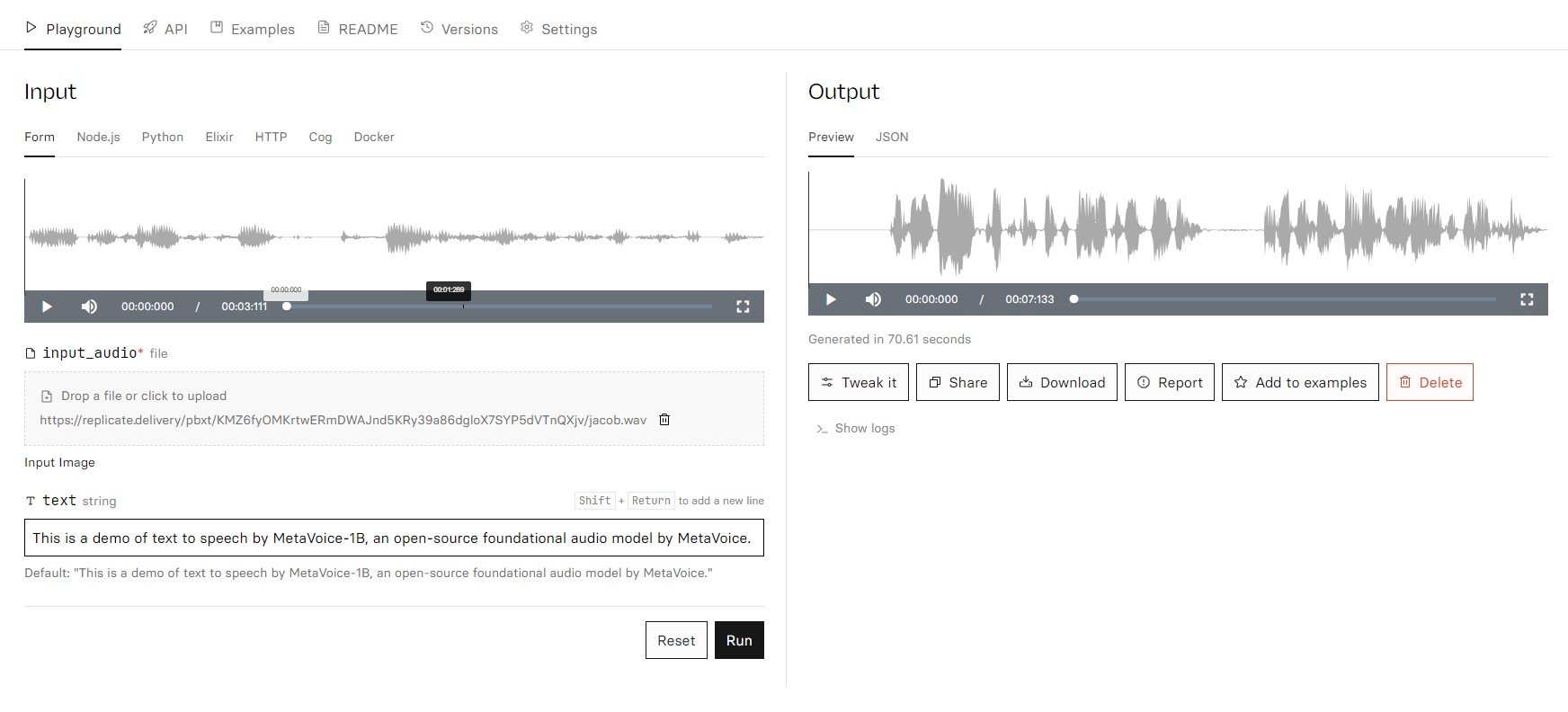
MetaVoice-1B: 1.2B parameter base model trained on 100K hours of speech

Diffusion Models for Image Morphing

Bokeh Prediction, a hybrid bokeh rendering framework that combines a neural renderer with a classical approach. It generates high-resolution, adjustable bokeh effects from a single image and potentially imperfect disparity maps.

Base version of Mamba 1.4B, a 1.4 billion parameter state space language model

Implementation of Realistic Vision v5.1 with VAE

Animation Studio on Stable Diffusion via Dreambooth

The Yi series models are large language models trained from scratch by developers at 01.AI.

Generating object-level shape variations with Stable Diffusion

MiniGPT-4 w/ Vicuna-7B (Image Question/Captioning Use)

replace background with Stable Diffusion and ControlNet
