
SDXL fine-tuned on both Barbie and Tron Legacy

Video Object Segmentation, combined with SAM and ProPainter

MagicTime: Time-lapse Video Generation Models as Metamorphic Simulators

Real-ESRGAN with optional face correction and adjustable upscale

Qwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data

Uses pixray with raw settings.

Arcane on Stable Diffusion via Dreambooth

Stable diffusion, but with more powerful in-painting & out-painting capabilities

A very blocky and bold cartoon style with some anime elements. You should use daiton style to trigger the image generation.

Honeycomb NLQ Generator
pixray text2image (future branch)

Create videos from illustrated input images

Robust face restoration algorithm for old photos / AI-generated faces

Detect Animals, Vehicles and Humans in Camera Trap Imagery
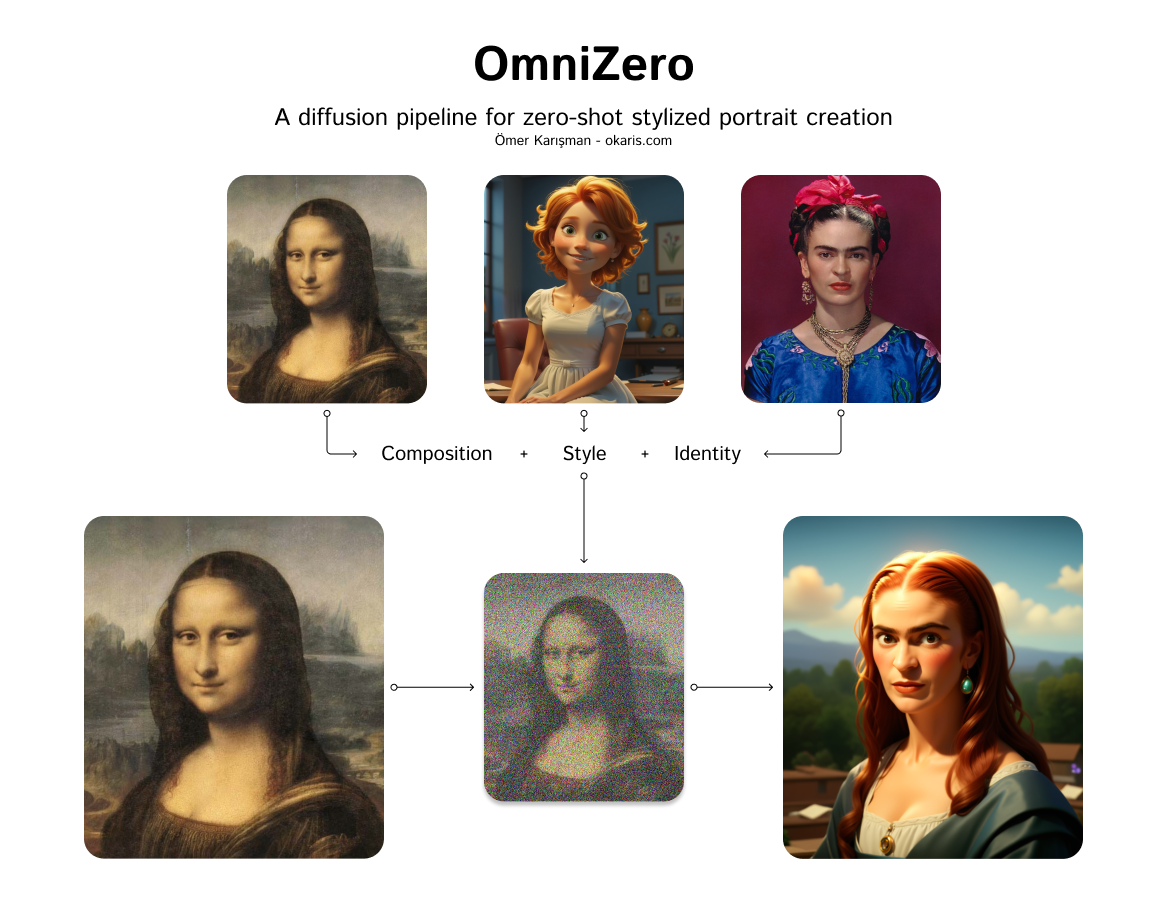
Omni-Zero: A diffusion pipeline for zero-shot stylized portrait creation.

Midjourney v6 text-to-image quality model but Open and Decentralized

Modify images using human pose

To explore stablebooth (training and prompts) trained on pictures of James!

A deep learning approach to remove background & adding new background image

Trained on 65 NYC Dive Bar Bathrooms
